Contexto
Mesmo adorando usar docker, principalmente porque ele tem uma interface :heart_eyes:
acabei tendo que buscar alternativas, já que ele começou ser pago para empresas, sempre tentei compartilhar a liberdade que existe em usar um ambiente dentro de um container.
Pra mim é algo mágico poder simplesmente matar o container e fazer de novo, sem medo de perder algo, ou até mesmo pedir pra alguém testar algo.
enfim…
um dos meus projetos é apresentar alguns environments para outras pessoas, afinal é mais prático você apresentar algo á alguem usando o recurso do que pedindo pra pessoa estudar
em minhas conversas sempre é o mesmo papo, pergunto se a pessoa conhece docker, e no final a pessoa geralmente fala “já ouvi falar, mas nunca usei”, quando isso acontece eu tenho a oportunidade mais divertida, porque hoje eu compartilho minha tela e começo mostrando como é “dificil” subir alguma coisa, eu escolho o item mais simples que conheço: rabbitmq que por um acaso é um outro amor que tenho 😀
Exemplo de subir uma imagem
compartilho geralmente meu repositório de environments
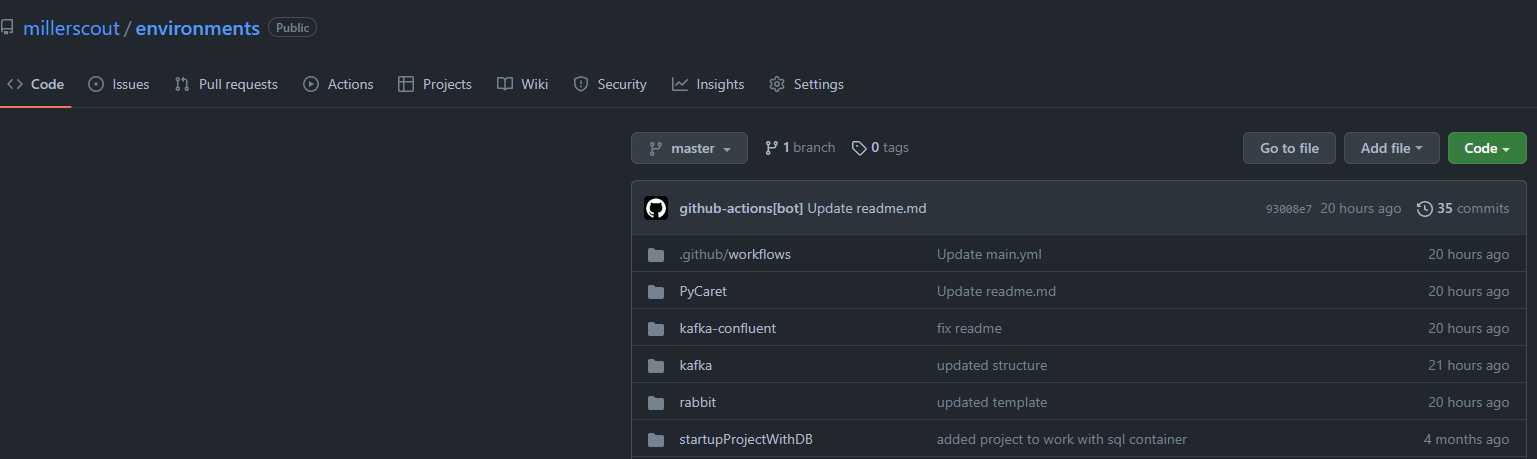
então abro um console e digito:
git clone https://github.com/millerscout/environments.git
cd environments
cd rabbit
cd Default
docker-compose up

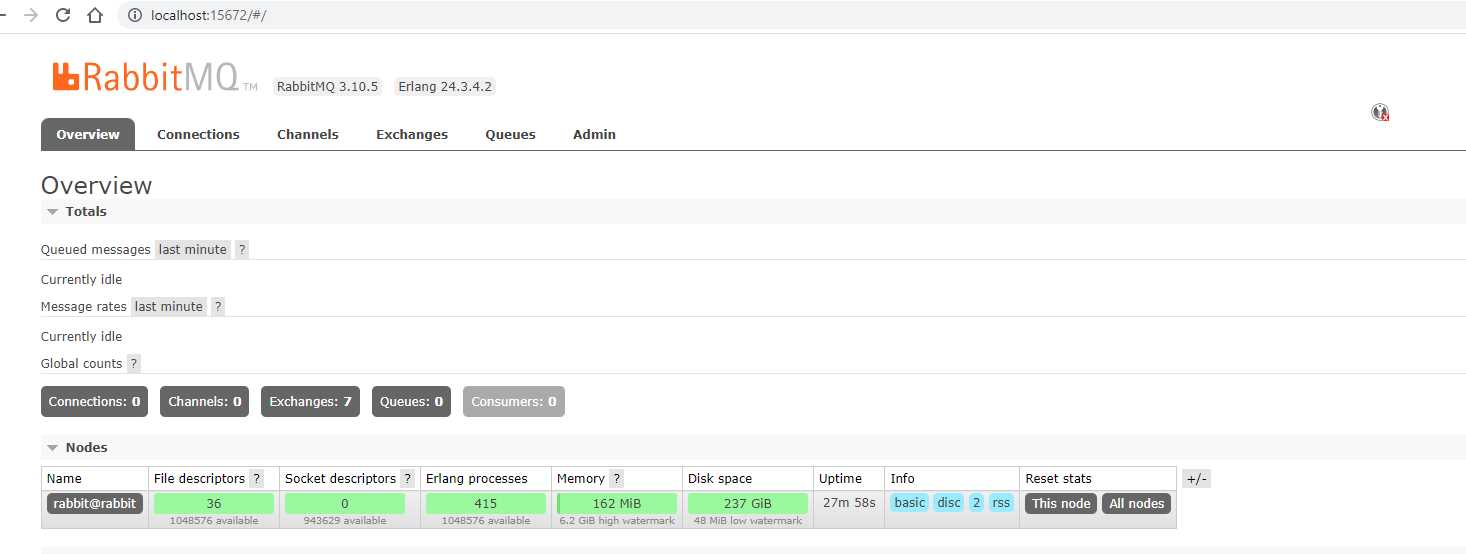
e Voilá! tá pronto, só abrir o localhost:15672

logo com user guest e senha guest e pronto
é tão simples que acaba sendo mais fácil ainda quando eu mostro como eu fiz, no docker-compose.yml
não é nada mais nada menos que só isso:
version: '3'
services:
rabbitmq:
image: "rabbitmq:3-management"
hostname: "rabbit"
ports:
- "15672:15672"
- "5672:5672"
labels:
NAME: "rabbitmq"
configurando o podman
bom primeiro eu tive que instalar o podman (duh?!)
tive que instalar um script em python para funcionar o podman-compose, tudo instalado, tranquilamente
mas quando executei: podman-compose up
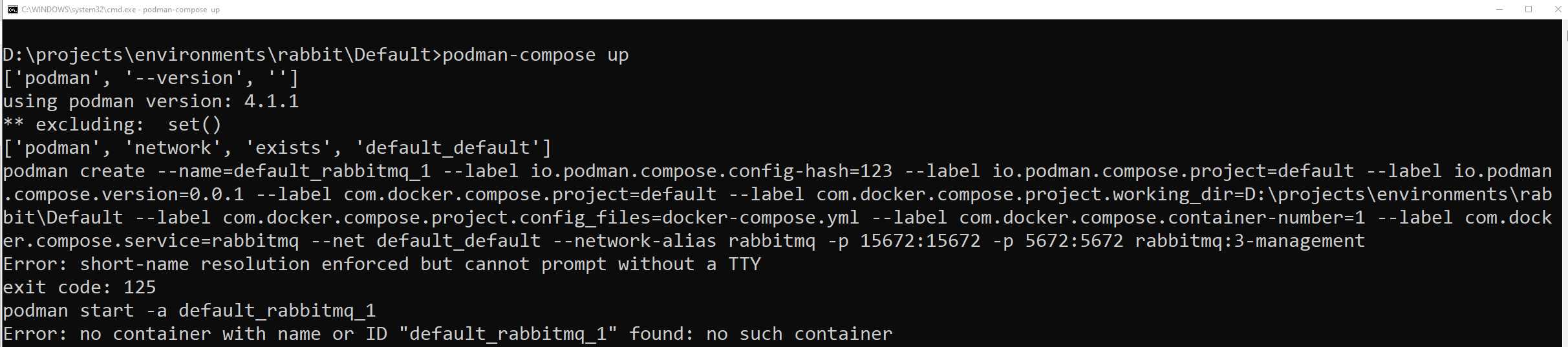
sem sucesso acabei fazendo o que todo dev experiente faz, abri o google e pesquisei :scream:
e achei dois posts que são importantes:
https://github.com/containers/podman/issues/11530 que é o “problema” que eu tenho
https://www.redhat.com/sysadmin/container-image-short-names que é a explicação do motivo que acontece.
então acabei alterando meu yml pra funcionar tanto com podman quando docker apenas acrescentando a origem da imagem
version: '3'
services:
rabbitmq:
image: "docker.io/library/rabbitmq:3-management"
hostname: "rabbit"
ports:
- "15672:15672"
- "5672:5672"
labels:
NAME: "rabbitmq"
sim… somente essa mudança.
bom, agora que você sabe como rodar isso tanto em docker quanto em podman, vai lá e começa brincar e compartilhar com alguém do seu time que ainda não está usando 😀
até mais
Esteja Curioso!


