Onde paramos mesmo?
Em nosso último Snapshot tivemos esse resultado

nosso TodoList é pra tentar diminuir o tempo e agora carregar os dados on-demand.
O commit até o momento Commit
Removi algumas propriedades e processamento inútil, o snapshot ficou:

Ainda não descobri o motivo que deu ~12segs de diferença quando eu removi as coleções inúteis, sei que melhorou o gen0 e gen 1, não vou focar nisso agora, porque estive fazendo vários experimentos, fazendo buffering a asyncwrite mas acabou dando na média de 60seg.
Voltarei no tempo de leitura, quando estiver refatorando a leitura de arquivo especificamente
Encontrei um novo problema.
Apesar de ter indexado todos os valores e poder acessar rapidamente, conforme o print.
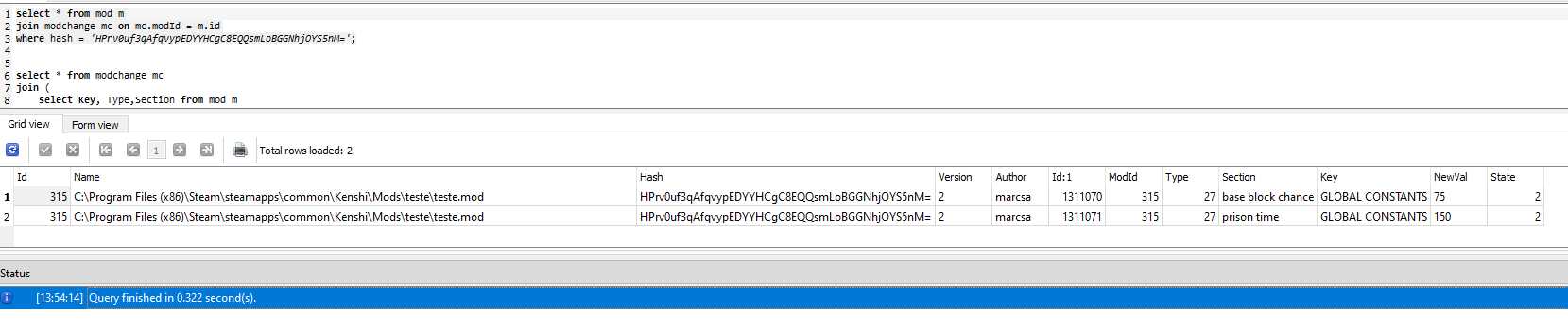
Ainda tenho o desafio de ter que pesquisar no sqlite a informação com o Tipo, Key e section
o que se resume em :
select * from modchange mc
join (
select Key, Type,Section from mod m
join modchange mc on mc.modId = m.id
where hash = 'HPrv0uf3qAfqvypEDYYHCgC8EQQsmLoBGGNhjOYS5nM='
) mcd on mcd.key = mc.key and mcd.Type = mc.type and mcd.section = mc.section
Porém ao executar temos 17Segs de execução.
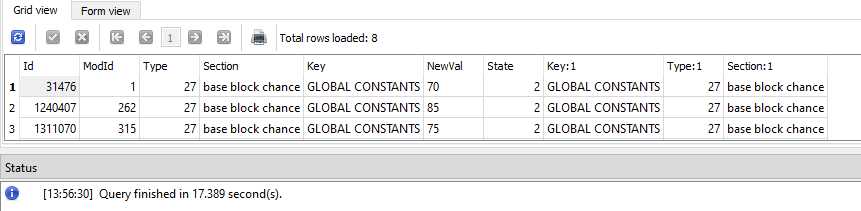
o que acaba sendo inviável.
Uma solução que pensei foi transformar key,type e section em um identificador único, e então usar como chave, tornando o processo muito mais rápido na pesquisa.
NOTA: enquanto estava fazendo o hash das 3 string, o tempo foi pra 2 minutos!,
então removi o Type, já que ele já é um Enum, não precisa participar da criação do hash
Eis o resultado em disco e tempo:

O tempo médio pra processamento está em cerca de 1 minuto e 130MB salvo em disco, mas eu acho que está ruim, apesar de ser a primeira execução, eu quero que fique em torno de 30 segundos.
São aproximadamente 1kk de alterações. mais ou menos 43k de changes por segundo.
Depois de descansar, voltei ao problema.
Fiquei um tempo tentando usar hash, tirando daqui, mudando ali pra ter um tempo menor… então me lembrei que eu tinha esquecido de fazer algo BEM mais simples que resolveria o problema, eis o código em sql:

CREATE INDEX idx_mod_change ON ModChange (Key,Type,Section);
o resultado, como esperado:
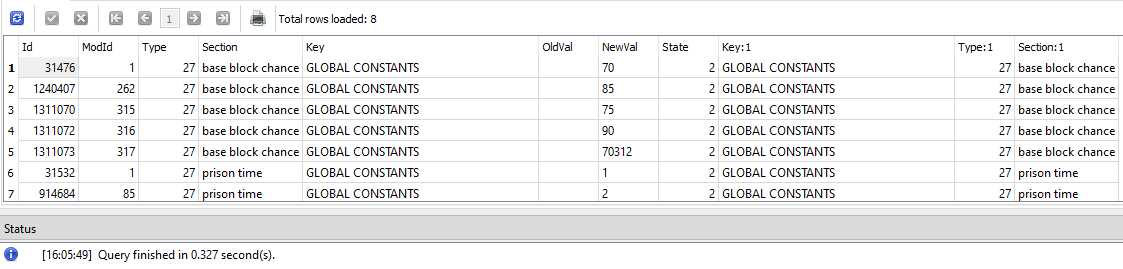
pois é, as vezes você está tão focado em um cenário que acaba deixando passar os detalhes mais simples, no meu caso eu parei pra descansar, assistir filme e tirar o dia pra desansar, voltei e imitei o panda ao perceber o que tinha deixado pra trás.
era isso por hoje.
Esteja Curioso!
