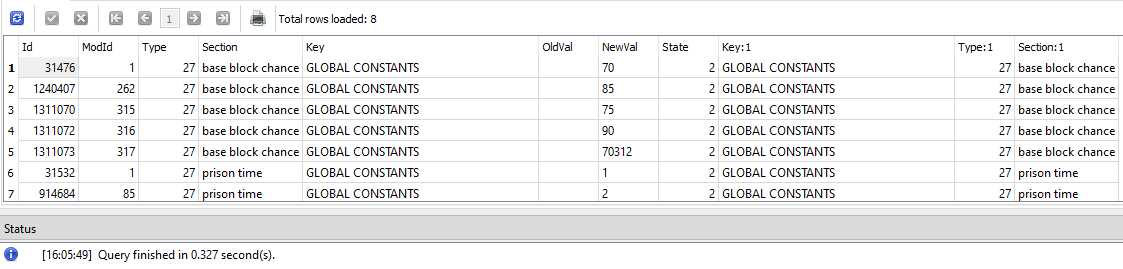
Onde paramos mesmo?
Em nosso último Snapshot tivemos esse resultado
Gen 0: 187
Gen 1: 72
Gen 3: 11
Tempo: 13179ms
Memória: 590mb
Meu objetivo agora era parar de ficar perdendo tempo re-processando todos os mods, não fazia sentido.
Há várias soluções que podemos aplicar, a mais simples “pra mim”, seria utilizar um Helper que fiz pra SqlLite sendo assim eu iria facilitar e muito a quantidade de código que eu escreveria.
Primeiro problema
Fui percebendo que estava fazendo uma iteração desnecessária, pois eu já estava carregando os dados do Mod na memória, depois de terminar de ler tudo eu iterava de novo só pra identificar as modificações… mas isso é redundante e o resultado era apenas ter o valor “Old”.
Porém como os mods podem ser re-ordenados o “Old” se mudará conforme o contexto, logo… é uma informação inútil.
Resultado: Remoção desses código inúteis.
Segundo problema
Eu estava usando minha Library então, o passo mais simples seria abrir uma connection com o banco e ir salvando no DB, algo como:
var db = new DataService();
db.Insert(query, parametros);
sim… é só isso
o único problema é que não estou inserindo 10 itens, e sim mais de 500K, então meio que ele ficou processando por mais de 1 hora e não havia terminado (eu dei uma pausa pra descansar, ele ficou processando enquanto isso) logo precisava efetuar otimizações… (que novidade :x)
Mas eu já esperava isso, eu havia encontrado uma forma eficiente em SqlLite que itera e insere os dados, um dia eu posto mais detalhes (talvez)
o código no final ficou:
static Dictionary[] List = new Dictionary[5000];
static int lastIndex = 0;
public static void AddToList(int id, ItemType type, string key, string name, string empty, string flag2, State state)
{
List[lastIndex] = new Dictionary(7)
{ { "ModId", id },
{"Type" , type },
{"Section" , key },
{"Key" , name },
{"OldVal" , string.Empty },
{"NewVal" , flag2 },
{"State" , state },
};
lastIndex++;
if (lastIndex > 5000)
{
var db = new DataService();
db.InsertBatch(@"INSERT INTO ModChange (
ModId,
Type,
Section,
[Key],
OldVal,
NewVal,
State
)
VALUES (
:ModId,
:Type,
:Section,
:Key,
:OldVal,
:NewVal,
:State
)", List.Take(lastIndex));
List = new Dictionary[5000];
lastIndex = 0;
}
}
Bom um pouquinho grande, mas dá pra entender, eu coloquei cada batch pra 5k de registro, me parecia ser suficiente, mas vamos ver como ficou o resultado no GC?
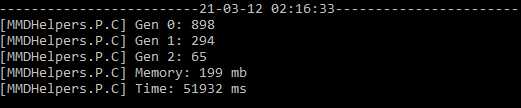
É… mais uma vez aumentamos a quantidade de varreduras do GC, mas o que podemos fazer pra resolver isso?
Nós estamos criando uma lista de dictionary, que depois será criado transformado em uma lista de parameters conforme o código aqui
vamos resolver isso criando uma lista de parameters.
static SQLiteParameter[][] List = new SQLiteParameter[12000][];
static int lastIndex = 0;
public static void AddToList(int id, ItemType type, string key, string name, string empty, string flag2, State state)
{
if (lastIndex == 12000)
{
UpdateDatabase();
}
List[lastIndex] = new SQLiteParameter[7] {
new SQLiteParameter("ModId", id),
new SQLiteParameter("Type", type),
new SQLiteParameter("Section", key),
new SQLiteParameter("Key", name),
new SQLiteParameter("OldVal", empty),
new SQLiteParameter("NewVal", flag2),
new SQLiteParameter("State", state)
};
lastIndex++;
}
public static void UpdateDatabase()
{
var db = new DataService();
var query = @"(..query..)";
using (var connection = new SQLiteConnection($"Data Source={DataService.DbLocation}; Version=3;"))
{
connection.Open();
using (var transaction = connection.BeginTransaction())
using (var command = connection.CreateCommand())
{
command.Prepare();
command.CommandText = query;
foreach (var item in List.Take(lastIndex))
{
command.Parameters.AddRange(item);
command.ExecuteNonQuery();
}
transaction.Commit();
}
}
lastIndex = 0;
}
resultado:
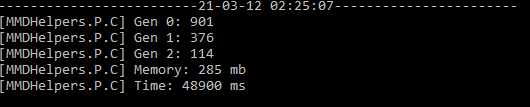
o resultado pra mim é simbólicamente o mesmo, mas por que será que não houve melhora?
existem duas coisas que pioram a vida:
– GC sendo executado com frequência porque tem objeto que não está sendo usado.
– Alocar algo na memória tem seu custo..
mas e se não criarmos mais objetos que precisamos usar?
bom, fiz a adequação no código
static SQLiteParameter[][] List = new SQLiteParameter[5000][];
static int lastIndex = 0;
public static void AddToList(int id, ItemType type, string key, string name, string empty, string flag2, State state)
{
if (lastIndex == 5000)
{
UpdateDatabase();
}
if (List[lastIndex] == null)
{
List[lastIndex] = new SQLiteParameter[7] {
new SQLiteParameter("ModId", id),
new SQLiteParameter("Type", type),
new SQLiteParameter("Section", key),
new SQLiteParameter("Key", name),
new SQLiteParameter("OldVal", empty),
new SQLiteParameter("NewVal", flag2),
new SQLiteParameter("State", state)
};
}
else
{
List[lastIndex][0].Value = id;
List[lastIndex][1].Value = type;
List[lastIndex][2].Value = key;
List[lastIndex][3].Value = name;
List[lastIndex][4].Value = empty;
List[lastIndex][5].Value = flag2;
List[lastIndex][6].Value = state;
}
lastIndex++;
}
public static void UpdateDatabase()
{
var db = new DataService();
var query = @"INSERT INTO ModChange (
ModId,
Type,
Section,
[Key],
OldVal,
NewVal,
State
)
VALUES (
:ModId,
:Type,
:Section,
:Key,
:OldVal,
:NewVal,
:State
)";
using (var connection = new SQLiteConnection($"Data Source={DataService.DbLocation}; Version=3;"))
{
connection.Open();
using (var transaction = connection.BeginTransaction())
using (var command = connection.CreateCommand())
{
command.Prepare();
command.CommandText = query;
foreach (var item in List.Take(lastIndex))
{
command.Parameters.AddRange(item);
command.ExecuteNonQuery();
}
transaction.Commit();
}
}
lastIndex = 0;
}
resultado:

Vou encerrar por aqui,
mas para nossa TODO list temos:
– Processar somente os arquivos novos.
– implementar o carregamento de conflitos no frontend on-demand
– remover mais campos que não usamos pra ter mais eficiência.
– revalidar partes do código que só são sujeira.
Bom é isso, até o próximo post
Esteja curioso!